Zookeeper
This post explore Zookeeper: Post, a service for coordinating processes of a distributed application with elements like group messaging, shared registers and distributed lock service in a centralized replicated service
Introduction
Locking is a powerful coordination primitive. Chubby provides a strong locking service with strong synchronization guarantees, locks then can be used to implement leader election group membership, etc. Zookeeper is also designed to be a “coordination kernel”, provides core-services, upon which specific primitives are developed by application developers. Zookeeper does not rely on blocking primitives such as locks to avoid problems like fault/slow clients slowing down others and the implementation itself becomes complicated with timers etc. being used. Instead “wait-free” data objects (znodes) organized as a hierarchial file-system (data tree). The API for this resembles Chubby without the locking open and close methods.
This wait-free property is important for performance and fault-tolerance, but for coordination they enforce FIFO client ordering of all operations and linearizable writes. Also it follows a pipelined architecture that allows outstanding transactions and still maintains low latency. Caching on the client is not managed by Zookeeper unlike chubby (eg. in the master, an update is blocked until all clients invalidate the cached data), perform the operation if the version.
Clients connecting to zookeeper obtain a session handle. Each session has a timeout, and a session it terminated explicitly by the client (via the session handle) or when the timeout expires (when zookeeper considers these clients as faulty).
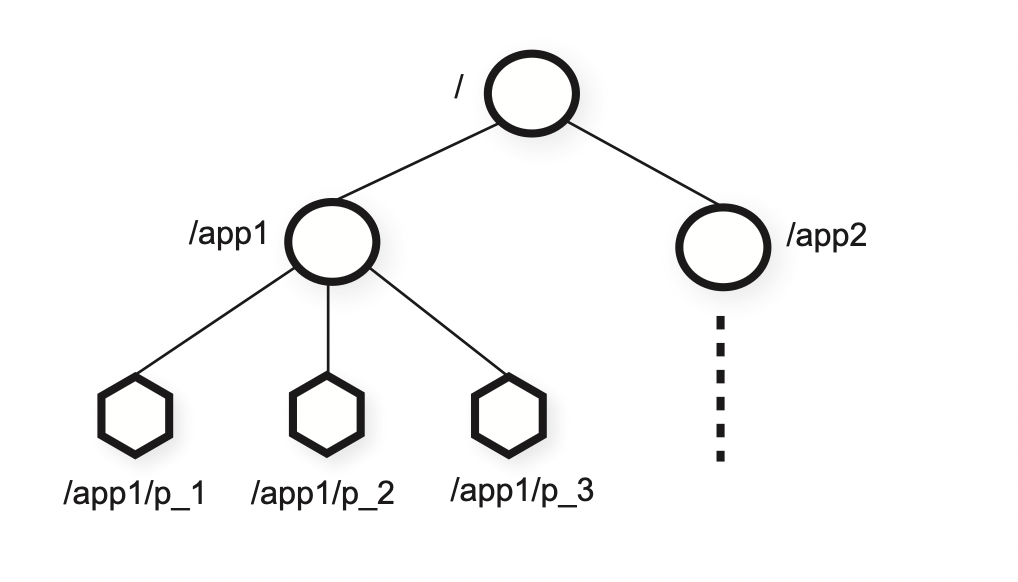
Znodes in Zookeeper are referenced by UNIX notation (/A/B/C). There are two types of znodes: Regular (client explicitly manage by creating and deleting) and Ephemeral nodes (similar to regular but system can remove if the session that create them terminates). All znodes store data and all znodes except ephemeral znode can have children. Additionally, client can send a sequential flag that allows a number to be appended to the znode’s name that is higher than all of the sequential znodes created under its parent. Zookeeper allows client to have watches - they receive a notification of change without need to poll. These watches are one-time triggers associated with a session, unregistered when triggered once or when session closes.
The data model is like a file-system (k-v store with hierarchial keys). The znodes are not designed for general data storage, use-cases like creation of znodes by each client to indicate group membership. But clients can store information/meta-data like current leader can store its information in a common file.
The client apis (like create, exists, getData, setData, etc.) have synchronous and asynchronous versions. Applications use the synchronous version when they have to execute a single operation so it calls and blocks. The async api allow to have multiple outstanding transactions and other tasks executed in parallel. Zookeeper guarantees that callbacks to the operations are executed in-order [[ what are callbacks and why is this required, also shouldn’t these operations be executed because of the state change property ]]. Zookeeper does not use handles to access znodes and uses znode paths and version no. (no open and close methods needed and eliminated extra state that the server would need to maintain - like in Chubby)
Guarantees
“ZooKeeper’s ordering guarantees allow efficient reasoning about system state, and watches allow for efficient waiting”
- Linearizable writes: all updates to the state are serializable and respect precedence.
- FIFO client orders: requests are executed in the order they were sent from the clients.
Because only updates are A-serializability (async linearizability) Zookeeper processes read requests locally at each replica [[ have to understand what/how ]]
Liveliness and durability guarantees
- it is available as long as a majoriy of nodes are up
- if zookeeper response successfully to a update, then the update persists across a number of failures as long as a quorum of server are eventually able to recover.
Example on the use of these guarantees: Consider a master and worker application using zookeeper for coordination. The requirement is that
- master has to update configurations and while the update is happening, the workers should not start using the configuration
- if the master fails before the configuration is fully updated, the workers should not use the configuration
Distributed locks like Chubby handle req 1 but not req 2. This is handled as follows, the system has a ready znode which the master deletes when its updating configuration znodes, and when its done with the update it puts it creates ready znode. The workers wait until the ready znode get created to start reading its configuration. “Because of the guarantee if the process sees the ready znode then it has to see the updated configuration”. If the master dies then the ready znode is never created back and the workers do not use the current configuration.
Primitives
- Dynamic Configuration management: Processes are a configuration stored as a znode with the watch flag as true. If the configuration is ever updated the processes get notified and can read the new configuration
- Rendezvous node: client passes the full path of the znode to the master who upon startup enters its details (address/port/etc), the workers upon starting use this information to connect to the master.
- Group membership: ephemeral nodes can be created under a specific node to indicate membership, these names of the node can be something unique that each group member has inherently or they can use the sequential flag to create numbered node.
- Simple locks: clients try to create a designated znode with ephemeral flag, if create succeeds the client holds the lock, else it sets the watch flag and tries again when the lock is release (after it gets notified due to watch). Problems with this are its suffers from herd effect (all clients are contending and only 1 will succeed) and this is only exclusive locks.
- Locks without herd effect: Client create sequential locks (ephemeral znode) inside a znode. They check if in the znode a lock with lower no. exists if yes they watch this znode (then they try again when watch is triggered) else this client has the lock.
- Read/Write locks: Write locks are implemented similar to locks without herd effect (names start with “write-“) and for read locks they check if any write locks exists before them (write lock znodes with lower sequential no)
- Barrier: For creating a synchronization barrier clients create a node under a fixed node. When the process creating a node reaching the threshold no. it also creates a ‘ready’ node that other client watch on to enter the barrier. To exit the processes watch for another child to disappear and then check if all children are removed.
These primitives provided by Zookeeper are used in a no of application in Yahoo and otherwise:
- Yahoo Crawling service uses it for configuration management and leader election.
- Katta (distributed indexer) uses it for group membership, leader election when master failover and assignment of shards to slaves (configuration management)
- Yahoo Message Broker (YMB)
ZNode diagram

Implementation
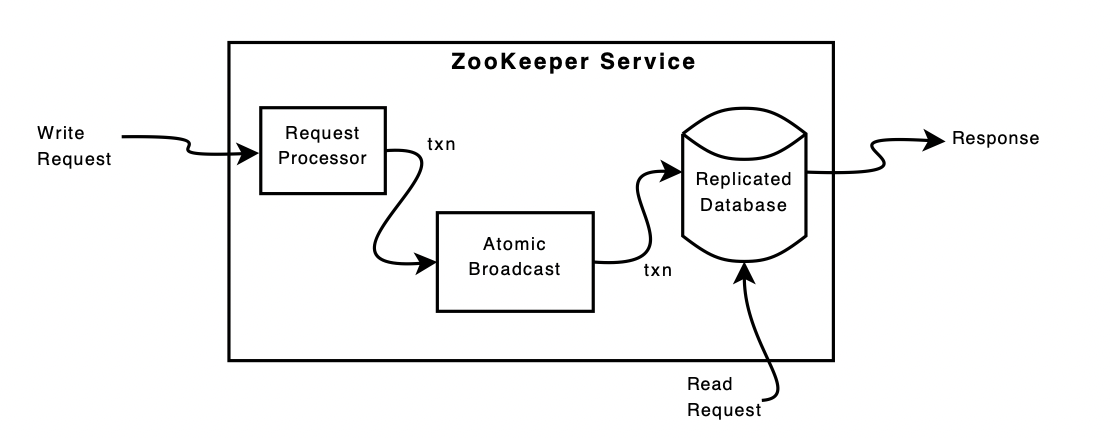
- Write requests that require an agreement among the servers go though the Atomic broadcast protocol and finally get committed in the db.
- The DB is maintained in-memory containing the entire data tree (znodes) and like Chubby has a replay log (write ahead log) of committed operation and periodic snapshots are written to NVM.
- Reads are served locally from the db.
- Clients connect to any one zookeeper server. Writes are sent to the zookeeper leader upon which it gets agreement from followers to commit, reads are calculated locally.
Transaction created are idempotent (which may not be the case for client requests), a zookeeper leader gets the write from the client, calculates the state in which it will be and creates a transaction which captures this change. This is part of the request processor pipeline. We talked about ZAB in the previous post. To achieve higher throughput, Zookeeper uses pipelining to have many requests at different stages in the diagram above. Leader choosen by Zab is used as the Zookeeper leader and Zab has guarantees to deliver messages in order.
Zookeeper stores periodic snapshots in the db and these are called fuzzy snapshots are the zookeeper state is not locked when taking this snapshot. This is acceptable as transactions stored in log can be re-applied (in the correct order) to get back the correct state.
Leader processes only a single the write and no other write/read concurrently. Read, as mentioned before are processes locally at each server which gives excellent performance as no disk activity of ZAB protocol to be done. The con is that reads may give stale value and for applications that requires the latest value there is a sync primitive.
Client could connect to a new server, in which case it is checked whether the server has the state at-least until the last zxid (a tag done by the server for client read requests) as seen by the client. Session is not established otherwise and the client can find another server as a majority will exist. Sessions are governed by timeouts within which either the client should send heartbeat or any other request.
Note
- Please let me know if I misinterpreted or missed something.