Paxos in Practice
Building upon the previous post on Paxos, this post explores the challenges in implementing Paxos through the Paxos Made Live paper.
Aim
The algorithm described earlier in the Paxos post is not so concise when it comes to actual code considering all the fault handling to make it production ready, and various other development and operational reasons. The aim of the authors is to build a fault tolerant log using Paxos, Chubby, a fault tolerant system to provide distributed locking mechanism. Each datacentre typically has one Chubby instance (“cell”) which other applications use. A cell consists of 5 replicas, every Chubby object is stored as an entry in a db and the db is replicated. At any one time, one replica is considered to be a master (new master elected upon failure), and clients contact it for service.
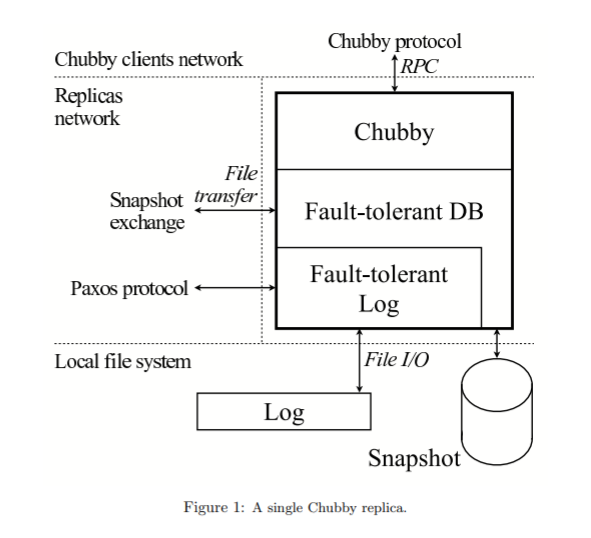
The fault tolerant replicated db consists of the local snapshot and the replay log of db operations. New operations are submitted to the log to be replicated and then applied to the local db. Chubby uses the db to store its state.
Challenges with using Paxos
Multi Paxos is used to achieve consensus on a sequence of values in the log. Submitting a value to Paxos -> executing an instance of Paxos while submitting that value.
-
Handling Disk Failures: Media failure or operator errors could render disks data to be unusable and the paxos replica can lose its state. If the file is accessible, but content are corrupted (checksum check) then the replica participates as a no voting member and uses catchup mechanism to get the state back.
-
Master leases: To avoid serializing reads through Paxos (as the volume is high, and we don’t want to run Paxos for every request) and as the master’s copy can have stale data if other replicas have elected a new master, they introduce master leases. If a master has a lease then it should be the only one to successfully submit values to Paxos and the replicas will not run an election until the lease expires. There are other caveats to this approach. Not explained very clearly.
-
Epoch numbers: Change in master should be handled. So an epoch number is used to determine if the request from an older master arrives (if the older master fails and new master takes over it picks a new epoch number). Need for this better explained in the Chubby paper - it is used to avoid responding to old packets and used during failover.
-
Changes in group membership must be handled, new nodes joining in or leaving the cluster.
- Snapshots: To prevent the log from growing too large and subsequently affect recovery time (operation applied sequentially from the log), we store a snapshot of the db and can delete the preceding log entries of the snapshot. This is independently done on each replica. This has its own concerns like
- as the db interface/application (in the diagram above) handles the db state/data structure and replicated log is handled separately by the Paxos framework, they need to be mutually consistent. So during the snapshot process, a snapshot handle (contain Paxos specific information to know what the snapshot relates to wrt the log) is passed.
- avoiding freeze in replica’s operating on the log while taking snapshot
- catch up mechanism needs to change: as other replicas will not have the whole log, the snapshot needs to be carried over and the current node can now fill any other entries after this state. Any failure or synchronization between learning and lagging replicas here should be handled.
- Snapshots can be transferred from local disk or remote backup e.g. GFS.
- Database transactions: the database needs to store KV pairs and support common operations. The cas (compare and swap) operation needs to be atomic across with respect to other db operations (probably issued on another replica), this is done by submitting the operations related to cas as a single value to Paxos. They come up with a MultiOp operation that acts like a db transaction with guard tests, operations to do on success and failure of the guard tests.
Software Engineering and Failures
- The core algorithm needed to be separated from the other logic of build a complex system, the authors created a compiler that translates the state machine specification (also developed) to c++ code. This separation helped detect any issue or make changes in the core algorithm and testing it.
- Runtime checks were done to detect any inconsistencies, for e.g. master regularly running checksum request to the db log.
- Rigorous testing was done separately to check safety (check system state is consistent and not required to make any progress) and liveliness (consistent and making progress) properties. Random fault injections of different kinds after being combined like network outages, file corruptions, hardware failures, etc. were applied to simulations to test the system.
- There were failure when operating the system in production. Instances of issue during upgrade/rollout also caused loosing data, discovering a bug in linux kernel, etc.
Note
- Please let me know if I misinterpreted or missed something.