Google File System
Summary of the paper: The Google File System
Assumptions
- uses commodity components that fail often
- used to store large size files, need not optimize for small ones
- largely streaming reads and some random reads, many large sequential writes(appends) and small writes at random positions(need not optimize for it)
- take care of concurrency for multiple client appending to same file
- high sustained bandwidth more important than latency
Architecture
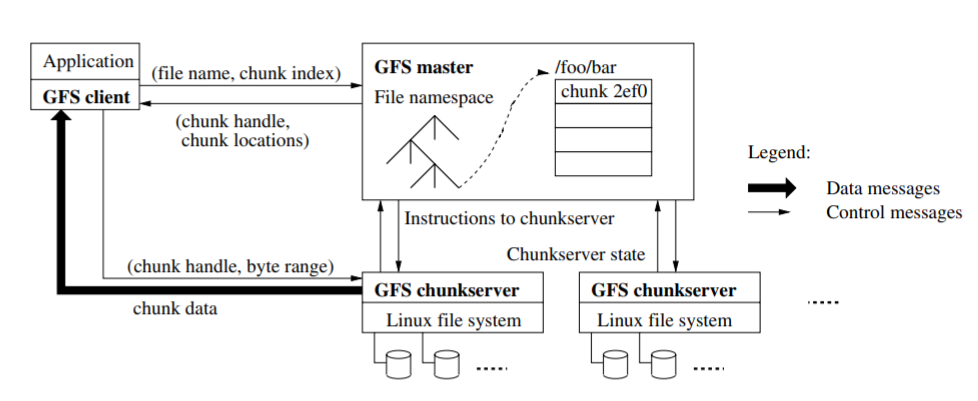
GFS manages files in chunks, a file is divided into fixed sized chunks (64MB, based on assumptions has its advantages and disadvantages) and each chunk has a unique identifier - chunk handle. GFS has a single master and multiple chunkservers. Master is responsible for managing files and chunks, storing metadata, status, garbage collection, migration, etc. Chunkservers store chunks in their local linux file systems and chunks are replicated onto multiple chunkservers. GFS client code is used to interact with the GFS system. A client communicates with the master to get metadata information and all data operations are done directly with the respective chunkservers. A client requests the master for metadata regarding a particular file and chunk index (calculated by know what byte offset it wants to perform a operation), this data is cached. The master responds with the chunk handler and the replicas that hold this chunk. The client then contacts chunkservers for the operation.
A single master makes placement and replication decisions with the global information. All metadata in kept in memory. The file and chunk namespace data and the file to chunks mappings are also persisted by logging metadata changes to a operation log (stored locally and replicated). When the master crashes it recovers its state by replaying the contents if the operation log The locations of each chunks replicas are not persisted, as they are updated periodically with the Heartbeat checks done on the chunkserver. Eliminates the problem of keeping master and chunkserver in sync during restarts, cluster membership changes, etc.
Operations
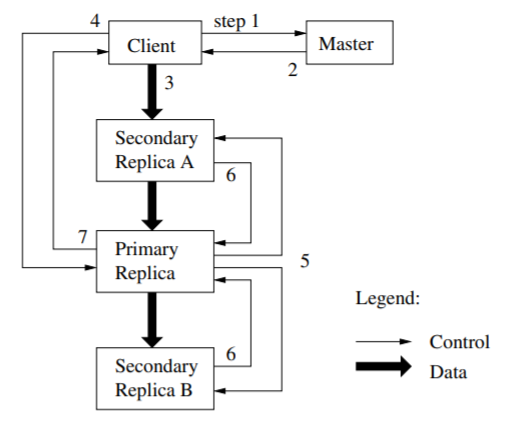
GFS provides common operations like snapshot and record append operations along with other common ones. Each mutation (any operation that changes the contents or metadata of a chunk like append, write) is performed at all replicas and needs to maintain an order to remain consistent. For this the master grants a chunk lease to one of the replicas making it a primary. Primary picks a serial order for all mutations to the chunk. The lease lasts for 60 seconds and can be renewed by the primary on if chunk is being mutated for longer. Control and data flow are decoupled. The client pushed the data to all replicas, and is stored in the buffer at the chunkserver. Once all servers acknowledge receiving the date, the client send the write request to the primary, the primary assigns consecutive serial no. to all mutations and applies to local state. It then sends the order to all replicas. Once all replicas have acknowledged, the primary replies to the client. Any errors encountered are reported to the client, it will make few attempts to retry. Data is pushed linearly than a tree fashion to utilize the machines outbound and inbound bandwidth. Forwarding is done to the server closest to it and done immediately as its received.
Record append operations are often done by multiple clients. Concurrent writes to the same region are not serializable: the region may end up containing data fragments from multiple clients. This mutation also follows the same flow as above with additional logic to handle if appends exceeds the current chunk size to be greater than 64MB. In general mutation with serial success are always in a defined state, while concurrent successes are consistent (across replicas) but undefined (may not be what the clients expect) and failure would leave the file regions in an inconsistent state. Snapshot operation are used to create copies of huge datasets quickly. Copy-on-write techniques are used to implement snapshots, when master receives a snapshot request it revokes any outstanding leases to create a new copy of the chunk first. It lets the current lease-holder know to create a copy of the chunk with new chunk handle and the replicas also, and then responds to the client which can then write to the chunk.
Master is responsible for the following activities:
- namespace management and locking: master uses locks to serialize operations on the regions of a namespace. Eg. the masters acquire read locks on d1/, d1/d2, etc and read or write lock on /d1/d2/d3/leaf on which doing an operation. This helps to prevent creation of files when a snapshot is being created.
- replica placement: other than replicating on different machines it also considers machines in different rack to avoid rack failure affecting the system. This also help in traffic and bandwidth availability.
- creation, re-replication and re-balancing: considering chunkserver with disk utilization, limiting the no of recent chunks (as traffic increases on that server) and rack placement. Re-replication is done as soon as the number of replicas are below a limit, with priority to blocking chunks. Chunks are copied from a replica. The master also re-balances periodically for balancing load and disk space.
- garbage collection: files when deleted are recorded in the log and rename to temporary with deletion timestamp (advantages over eager deletion, eg. safety net). They are removed after some days and also can be restored within that period by renaming. Orphaned chunks are identified during periodic scans, the chunks are free to delete chunks that are no longer present in the master’s metadata. Some disadvantages are that user cannot use the storage right away.
- stale replica detection: the master maintains the chunk version number to distinguish between up-to-date and stale replicas. The chunk version is updated when new lease is granted. Master failure or chunkserver failure leave the chunk versions locally to be stale and handled accordingly. The client also verifies that it has the latest chunk version no from a replica.
Fault tolerance and Availability
Faults are the norm rather than an exception at scale with the commodity servers: we cannot completely trust the machines nor the disks. High availability is possible through these strategies:
- fast recovery: state is restored in master and chunkserver in seconds on restart, servers are also routinely
- chunk replication: more complicated redundancy schemes can also be incorporated.
- master’s state is replicated for reliability, monitoring infra outside GFS restarts on failure, “shadow” masters provides RO access to the file system when the master is down.
Checksums to detect storage corruptions. Chunks are organized in 64 KB blocks and each blocks has a checksum associated. Checksums are kept in memory and persisted. GFS client reduces the overhead and aligns read at block boundaries. Optimized for appends (as only last partial checksum block need to be updated or new checksum for a new block), random writes have to go through the blocks check them first (to account any mistakes before), write new content and compute new checksums. When idle the chunkserver can check for corruption. Extensive and detailed logging of all RPC requests and responses for debugging and performance monitoring. Recent logs are kept in memory for continuous online monitoring.
Measurements
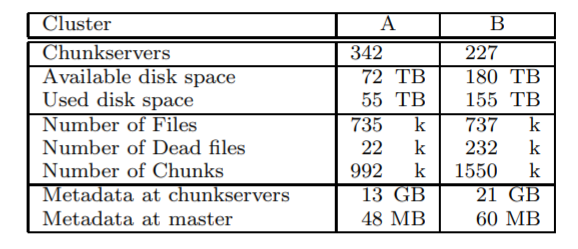
Test cluster - 16 chunkservers, 1 master 2 backups and 16 clients. 19 GFS machines were connected to a single switch and the 16 clients to another and a link between the switches. Read rate, write rate and appends were measured in different no of clients interacting with GFS and using different no of files. On real world cluster shown above the rates along with the load of operations on the master was calculated. Recovery time was calculated by failing servers randomly and noting time required for the chunks to restore the replicas. Another cluster was used to measure workloads on the chunkserver, master and note appends vs writes performance. For reads, writes and appends percentages of total operations for different sizes and percentages of total bytes transferred for different sizes are recorded.
Note
- Please let me know if I misinterpreted or missed something.